
жМЙпЉЪж≠§дЄЇеЃҐеЇІеНЪжЦЗз≥їеИЧгАВжКХз®њдЇЇеРіжЬ±еНОжЫЊеЬ®IBMдЄ≠еЫљз†Фз©ґйЩҐдїОдЇЛдЄОдЇСиЃ°зЃЧзЫЄеЕ≥зЪДз†Фз©ґпЉМзО∞еЬ®ж≠£иЗіеКЫдЇОз†Фз©ґдЇСиЃ°зЃЧжКАжЬѓгАВ
жЬђз≥їеИЧжЦЗзЂ†еЯЇдЇОеЕђеЉАиµДжЦЩеѓєGoogle App EngineзЪДеЃЮзО∞жЬЇеИґињЩдЄ™иѓЭйҐШињЫи°МжЈ±еЇ¶жОҐиЃ®гАВеЬ®еИЗеЕ•Google App EngineдєЛеЙНпЉМй¶ЦеЕИдЉЪеѓєGoogleзЪДж†ЄењГжКАжЬѓеТМеЕґжХідљУжЮґжЮДињЫи°МеИЖжЮРпЉМдї•еЄЃеК©е§ІеЃґдєЛеРОжЫіе•љеЬ∞зРЖиІ£Google App EngineзЪДеЃЮзО∞гАВ
жЬђзѓЗе∞ЖдЄїи¶БдїЛзїНGoogleзЪДеНБдЄ™ж†ЄењГжКАжЬѓпЉМиАМдЄФеПѓдї•еИЖдЄЇеЫЫе§Із±їпЉЪ
- еИЖеЄГеЉПеЯЇз°АиЃЊжЦљпЉЪGFSгАБChubby еТМ Protocol BufferгАВ
- еИЖеЄГеЉПе§ІиІДж®°жХ∞жНЃе§ДзРЖпЉЪMapReduce еТМ SawzallгАВ
- еИЖеЄГеЉПжХ∞жНЃеЇУжКАжЬѓпЉЪBigTable еТМжХ∞жНЃеЇУ ShardingгАВ
- жХ∞жНЃдЄ≠ењГдЉШеМЦжКАжЬѓпЉЪжХ∞жНЃдЄ≠ењГйЂШжЄ©еМЦгАБ12VзԵ汆еТМжЬНеК°еЩ®жХіеРИгАВ
еИЖеЄГеЉПеЯЇз°АиЃЊжЦљ
GFS
зФ±дЇОжРЬ糥еЉХжУОйЬАи¶Бе§ДзРЖжµЈйЗПзЪДжХ∞жНЃпЉМжЙАдї•GoogleзЪДдЄ§дљНеИЫеІЛдЇЇLarry PageеТМSergey BrinеЬ®еИЫдЄЪеИЭжЬЯиЃЊиЃ°дЄАе•ЧеРНдЄЇ"BigFiles"зЪДжЦЗдїґз≥їзїЯпЉМиАМGFSпЉИеЕ®зІ∞дЄЇ"Google File System"пЉЙињЩе•ЧеИЖеЄГеЉПжЦЗдїґз≥їзїЯеИЩжШѓ"BigFiles"зЪДеїґзї≠гАВ
й¶ЦеЕИпЉМдїЛзїНеЃГзЪДжЮґжЮДпЉМGFSдЄїи¶БеИЖдЄЇдЄ§з±їиКВзВєпЉЪ
- MasterиКВзВєпЉЪдЄїи¶Бе≠ШеВ®дЄОжХ∞жНЃжЦЗдїґзЫЄеЕ≥зЪДеЕГжХ∞жНЃпЉМиАМдЄНжШѓChunkпЉИжХ∞жНЃеЭЧпЉЙгАВеЕГжХ∞жНЃеМЕжЛђдЄАдЄ™иГље∞Ж64дљНж†Зз≠ЊжШ†е∞ДеИ∞жХ∞жНЃеЭЧзЪДдљНзљЃеПКеЕґзїДжИРжЦЗдїґзЪДи°®ж†ЉпЉМжХ∞жНЃеЭЧеЙѓжЬђдљНзљЃеТМеУ™дЄ™ињЫз®Лж≠£еЬ®иѓїеЖЩзЙєеЃЪзЪДжХ∞жНЃеЭЧз≠ЙгАВињШжЬЙMasterиКВзВєдЉЪеС®жЬЯжАІеЬ∞жО•жФґдїОжѓПдЄ™ChunkиКВзВєжЭ•зЪДжЫіжЦ∞пЉИ"Heart-beat"пЉЙжЭ•иЃ©еЕГжХ∞жНЃдњЭжМБжЬАжЦ∞зКґжАБгАВ
- ChunkиКВзВєпЉЪй°ЊеРНжАЭдєЙпЉМиВѓеЃЪзФ®жЭ•е≠ШеВ®ChunkпЉМжХ∞жНЃжЦЗдїґйАЪињЗ襀еИЖеЙ≤дЄЇжѓПдЄ™йїШиЃ§е§Іе∞ПдЄЇ64MBзЪДChunkзЪДжЦєеЉПе≠ШеВ®пЉМиАМдЄФжѓПдЄ™ChunkжЬЙеФѓдЄАдЄАдЄ™64дљНж†Зз≠ЊпЉМеєґдЄФжѓПдЄ™ChunkйГљдЉЪеЬ®жХідЄ™еИЖеЄГеЉПз≥їзїЯ襀е§НеИґе§Ъжђ°пЉМйїШиЃ§дЄЇ3жђ°гАВ
дЄЛеЫЊе∞±жШѓGFSзЪДжЮґжЮДеЫЊпЉЪ
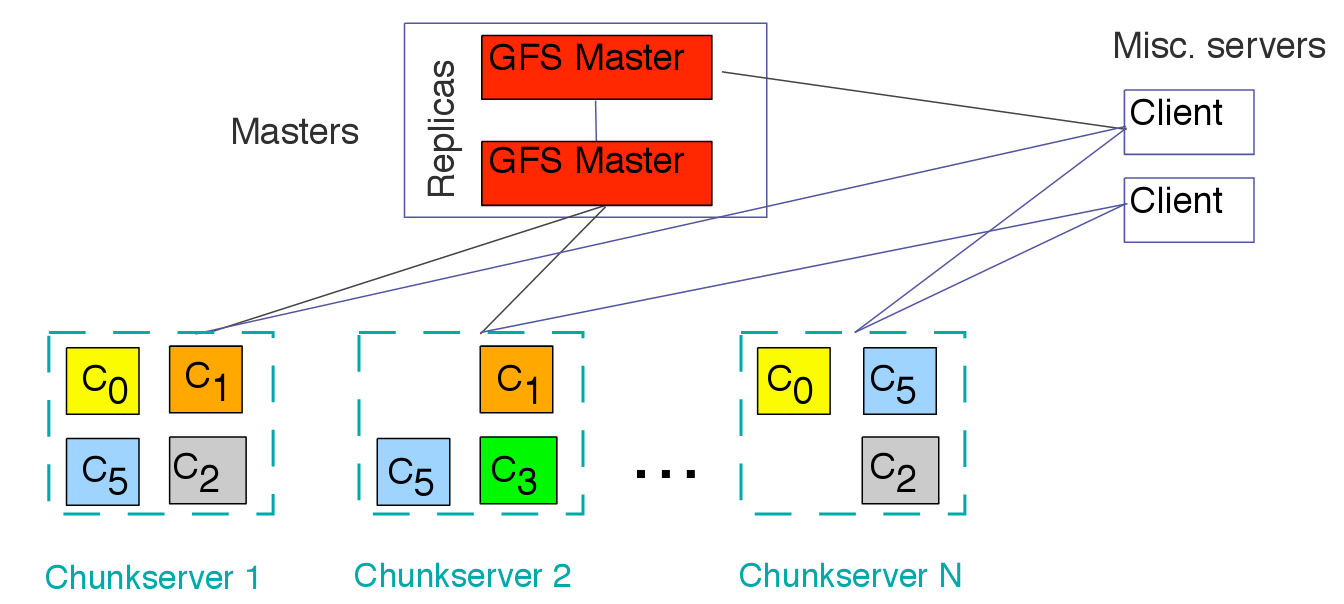
еЫЊ1. GFSзЪДжЮґжЮДеЫЊпЉИеПВзЙЗ[15]пЉЙ
жО•зЭАпЉМеЬ®иЃЊиЃ°дЄКпЉМGFSдЄїи¶БжЬЙеЕЂдЄ™зЙєзВєпЉЪ
- е§ІжЦЗдїґеТМе§ІжХ∞жНЃеЭЧпЉЪжХ∞жНЃжЦЗдїґзЪДе§Іе∞ПжЩЃйБНеЬ®GBзЇІеИЂпЉМиАМдЄФеЕґжѓПдЄ™жХ∞жНЃеЭЧйїШиЃ§е§Іе∞ПдЄЇ64MBпЉМињЩж†ЈеБЪзЪДе•ље§ДжШѓеЗПе∞СдЇЖеЕГжХ∞жНЃзЪДе§Іе∞ПпЉМиГљдљњMasterиКВзВєиГље§ЯйЭЮеЄЄжЦєдЊњеЬ∞е∞ЖеЕГжХ∞жНЃжФЊзљЃеЬ®еЖЕе≠ШдЄ≠дї•жПРеНЗиЃњйЧЃжХИзОЗгАВ
- жУНдљЬдї•жЈїеК†дЄЇдЄїпЉЪеЫ†дЄЇжЦЗдїґеЊИе∞С襀еИ†еЗПжИЦиАЕи¶ЖзЫЦпЉМйАЪеЄЄеП™жШѓињЫи°МжЈїеК†жИЦиАЕиѓїеПЦжУНдљЬпЉМињЩж†ЈиГљеЕЕеИЖиАГиЩСеИ∞з°ђзЫШзЇњжАІеРЮеРРйЗПе§ІеТМйЪПжЬЇиѓїеЖЩжЕҐзЪДзЙєзВєгАВ
- жФѓжМБеЃєйФЩпЉЪй¶ЦеЕИпЉМиЩљзДґељУжЧґдЄЇдЇЖиЃЊиЃ°жЦєдЊњпЉМйЗЗзФ®дЇЖеНХMasterзЪДжЦєж°ИпЉМдљЖжШѓжХідЄ™з≥їзїЯдЉЪдњЭиѓБжѓПдЄ™MasterйГљдЉЪжЬЙеЕґзЫЄеѓєеЇФзЪДе§НеИґеУБпЉМдї•дЊњдЇОеЬ®MasterиКВзВєеЗЇзО∞йЧЃйҐШжЧґињЫи°МеИЗжНҐгАВеЕґжђ°пЉМеЬ®Chunkе±ВпЉМGFSеЈ≤зїПеЬ®иЃЊиЃ°дЄКе∞ЖиКВзº姱賕иІЖдЄЇеЄЄжАБпЉМжЙАдї•иГљйЭЮеЄЄе•љеЬ∞е§ДзРЖChunkиКВзº姱жХИзЪДйЧЃйҐШгАВ
- йЂШеРЮеРРйЗПпЉЪиЩљзДґеЕґеНХдЄ™иКВзВєзЪДжАІиГљжЧ†иЃЇжШѓдїОеРЮеРРйЗПињШжШѓеїґињЯйГљеЊИжЩЃйАЪпЉМдљЖеЫ†дЄЇеЕґжФѓжМБдЄКеНГзЪДиКВзВєпЉМжЙАдї•жАїзЪДжХ∞жНЃеРЮеРРйЗПжШѓйЭЮеЄЄжГКдЇЇзЪДгАВ
- дњЭжК§жХ∞жНЃпЉЪй¶ЦеЕИпЉМжЦЗ俴襀еИЖеЙ≤жИРеЫЇеЃЪе∞ЇеѓЄзЪДжХ∞жНЃеЭЧдї•дЊњдЇОдњЭе≠ШпЉМиАМдЄФжѓПдЄ™жХ∞жНЃеЭЧйГљдЉЪ襀з≥їзїЯе§НеИґдЄЙдїљгАВ
- жЙ©е±ХиГљеКЫеЉЇпЉЪеЫ†дЄЇеЕГжХ∞жНЃеБПе∞ПпЉМдљњеЊЧдЄАдЄ™MasterиКВзВєиГљжОІеИґдЄКеНГдЄ™е≠ШжХ∞жНЃзЪДChunkиКВзВєгАВ
- жФѓжМБеОЛзЉ©пЉЪеѓєдЇОйВ£дЇЫз®НжЧІзЪДжЦЗдїґпЉМеПѓдї•йАЪињЗеѓєеЃГињЫи°МеОЛзЉ©пЉМжЭ•иКВзЬБз°ђзЫШз©ЇйЧіпЉМеєґдЄФеОЛзЉ©зОЗйЭЮеЄЄжГКдЇЇпЉМжЬЙжЧґзФЪиЗ≥жО•ињС90%гАВ
- зФ®жИЈз©ЇйЧіпЉЪиЩљзДґеЬ®зФ®жИЈз©ЇйЧіињРи°МеЬ®ињРи°МжХИзОЗжЦєйЭҐз®НеЈЃпЉМдљЖжШѓжЫідЊњдЇОеЉАеПСеТМжµЛиѓХпЉМињШжЬЙиГљжЫіе•љеИ©зФ®LinuxзЪДиЗ™еЄ¶зЪДдЄАдЇЫPOSIX APIгАВ
зО∞еЬ®GoogleеЖЕйГ®иЗ≥е∞СињРи°МзЭА200е§ЪдЄ™GFSйЫЖзЊ§пЉМжЬАе§ІзЪДйЫЖзЊ§жЬЙеЗ†еНГеП∞жЬНеК°еЩ®пЉМеєґдЄФжЬНеК°дЇОе§ЪдЄ™GoogleжЬНеК°пЉМжѓФе¶ВGoogleжРЬ糥гАВдљЖзФ±дЇОGFSдЄїи¶БдЄЇжРЬ糥иАМиЃЊиЃ°пЉМжЙАдї•дЄНжШѓеЊИйАВеРИжЦ∞зЪДдЄАдЇЫGoogleдЇІеУБпЉМжѓФYouTubeгАБGmailеТМжЫіеЉЇи∞Ге§ІиІД殰糥еЉХеТМеЃЮжЧґжАІзЪДCaffeineжРЬ糥еЉХжУОз≠ЙпЉМжЙАдї•GoogleеЈ≤зїПеЬ®еЉАеПСдЄЛдЄАдї£GFSпЉМдї£еПЈдЄЇ"Colossus"пЉМеєґдЄФеЬ®иЃЊиЃ°жЦєйЭҐжЬЙиЃЄе§ЪдЄНеРМпЉМжѓФе¶ВпЉЪжФѓжМБеИЖеЄГеЉПMasterиКВзВєжЭ•жПРеНЗйЂШеПѓзФ®жАІеєґиГљжФѓжТСжЫіе§ЪжЦЗдїґпЉМChunkиКВзВєиГљжФѓжМБ1MBе§Іе∞ПзЪДchunkдї•жФѓжТСдљОеїґињЯеЇФзФ®зЪДйЬАи¶БгАВ
Chubby
зЃАеНХзЪДжЭ•иѓіпЉМChubby е±ЮдЇОеИЖеЄГеЉПйФБжЬНеК°пЉМйАЪињЗ ChubbyпЉМдЄАдЄ™еИЖеЄГеЉПз≥їзїЯдЄ≠зЪДдЄКеНГдЄ™clientйГљиГље§ЯеѓєдЇОжЯРй°єиµДжЇРињЫи°М"еК†йФБ"жИЦиАЕ"иІ£йФБ"пЉМеЄЄзФ®дЇОBigTableзЪДеНПдљЬеЈ•дљЬпЉМеЬ®еЃЮзО∞жЦєйЭҐжШѓйАЪињЗеѓєжЦЗдїґзЪДеИЫеїЇжУНдљЬжЭ•еЃЮзО∞"еК†йФБ"пЉМеєґеЯЇдЇОиСЧеРНзІСе≠¶еЃґLeslie LamportзЪДPaxosзЃЧж≥ХгАВ
Protocol Buffer
Protocol BufferпЉМжШѓGoogleеЖЕйГ®дљњзФ®дЄАзІНиѓ≠и®АдЄ≠зЂЛгАБеє≥еП∞дЄ≠зЂЛеТМеПѓжЙ©е±ХзЪДеЇПеИЧеМЦзїУжЮДеМЦжХ∞жНЃзЪДжЦєеЉПпЉМеєґжПРдЊЫ JavaгАБC++ еТМ Python ињЩдЄЙзІНиѓ≠и®АзЪДеЃЮзО∞пЉМжѓПдЄАзІНеЃЮзО∞йГљеМЕеРЂдЇЖзЫЄеЇФиѓ≠и®АзЪДзЉЦиѓСеЩ®дї•еПКеЇУжЦЗдїґпЉМиАМдЄФеЃГжШѓдЄАзІНдЇМињЫеИґзЪДж†ЉеЉПпЉМжЙАдї•еЕґйАЯеЇ¶жШѓдљњзФ® XML ињЫи°МжХ∞жНЃдЇ§жНҐзЪД10еАНеЈ¶еП≥гАВеЃГдЄїи¶БзФ®дЇОдЄ§дЄ™жЦєйЭҐпЉЪеЕґдЄАжШѓRPCйАЪдњ°пЉМеЃГеПѓзФ®дЇОеИЖеЄГеЉПеЇФзФ®дєЛйЧіжИЦиАЕеЉВжЮДзОѓеҐГдЄЛзЪДйАЪдњ°гАВеЕґдЇМжШѓжХ∞жНЃе≠ШеВ®жЦєйЭҐпЉМеЫ†дЄЇеЃГиЗ™жППињ∞пЉМиАМдЄФеОЛзЉ©еЊИжЦєдЊњпЉМжЙАдї•еПѓзФ®дЇОеѓєжХ∞жНЃињЫи°МжМБдєЕеМЦпЉМжѓФе¶Ве≠ШеВ®жЧ•ењЧдњ°жБѓпЉМеєґеσ襀Map Reduceз®ЛеЇПе§ДзРЖгАВдЄОProtocol BufferжѓФиЊГз±їдЉЉзЪДдЇІеУБињШжЬЙFacebookзЪД Thrift пЉМиАМдЄФ Facebook еПЈзІ∞ThriftеЬ®йАЯеЇ¶дЄКињШжЬЙдЄАеЃЪзЪДдЉШеКњгАВ
еИЖеЄГеЉПе§ІиІДж®°жХ∞жНЃе§ДзРЖ
MapReduce
й¶ЦеЕИпЉМеЬ®GoogleжХ∞жНЃдЄ≠ењГдЉЪжЬЙе§ІиІДж®°жХ∞жНЃйЬАи¶Бе§ДзРЖпЉМжѓФе¶В襀зљСзїЬзИђиЩЂпЉИWeb CrawlerпЉЙжКУеПЦзЪДе§ІйЗПзљСй°µз≠ЙгАВзФ±дЇОињЩдЇЫжХ∞жНЃеЊИе§ЪйГљжШѓPBзЇІеИЂпЉМеѓЉиЗіе§ДзРЖеЈ•дљЬдЄНеЊЧдЄНе∞љеПѓиГљзЪДеєґи°МеМЦпЉМиАМGoogleдЄЇдЇЖиІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉМеЉХеЕ•дЇЖMapReduceињЩдЄ™зЉЦз®Лж®°еЮЛпЉМMapReduceжШѓжЇРиЗ™еЗљжХ∞еЉПиѓ≠и®АпЉМдЄїи¶БйАЪињЗ"MapпЉИжШ†е∞ДпЉЙ"еТМ"ReduceпЉИеМЦзЃАпЉЙ"ињЩдЄ§дЄ™ж≠•й™§жЭ•еєґи°Ме§ДзРЖе§ІиІДж®°зЪДжХ∞жНЃйЫЖгАВMapдЉЪеЕИеѓєзФ±еЊИе§ЪзЛђзЂЛеЕГзі†зїДжИРзЪДйАїиЊСеИЧи°®дЄ≠зЪДжѓПдЄАдЄ™еЕГзі†ињЫи°МжМЗеЃЪзЪДжУНдљЬпЉМдЄФеОЯеІЛеИЧи°®дЄНдЉЪ襀жЫіжФєпЉМдЉЪеИЫеїЇе§ЪдЄ™жЦ∞зЪДеИЧи°®жЭ•дњЭе≠ШMapзЪДе§ДзРЖзїУжЮЬгАВдєЯе∞±жДПеС≥зЭАпЉМMapжУНдљЬжШѓйЂШеЇ¶еєґи°МзЪДгАВељУMapеЈ•дљЬеЃМжИРдєЛеРОпЉМз≥їзїЯдЉЪеЕИеѓєжЦ∞зФЯжИРзЪДе§ЪдЄ™еИЧи°®ињЫи°МжЄЕзРЖпЉИShuffleпЉЙеТМжОТеЇПпЉМдєЛеРОдЉЪињЩдЇЫжЦ∞еИЫеїЇзЪДеИЧи°®ињЫи°МReduceжУНдљЬпЉМдєЯе∞±жШѓеѓєдЄАдЄ™еИЧи°®дЄ≠зЪДеЕГзі†ж†єжНЃKeyеАЉињЫи°МйАВељУзЪДеРИеєґгАВ
дЄЛеЫЊдЄЇMapReduceзЪДињРи°МжЬЇеИґпЉЪ
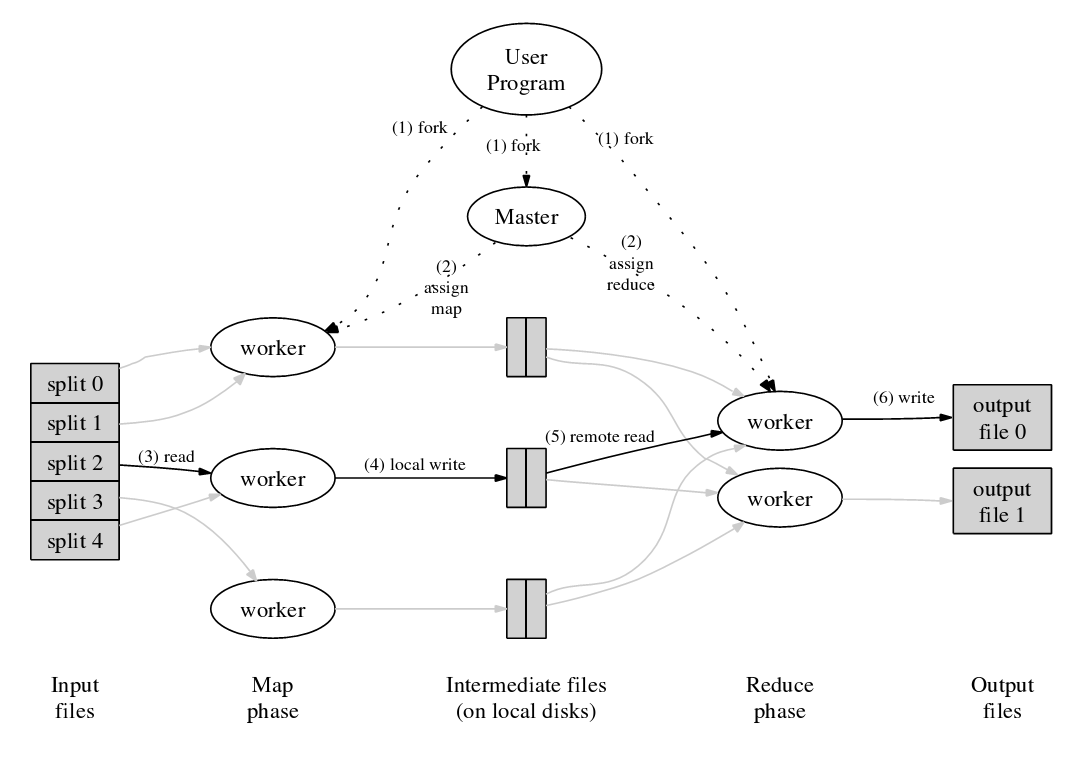
еЫЊ2. MapReduceзЪДињРи°МжЬЇеИґпЉИеПВ[19]пЉЙ
жО•дЄЛжЭ•пЉМе∞Жж†єжНЃдЄКеЫЊжЭ•дЄЊдЄАдЄ™MapReduceзЪДдЊЛе≠РпЉЪжѓФе¶ВпЉМйАЪињЗжРЬ糥Spiderе∞ЖжµЈйЗПзЪДWebй°µйЭҐжКУеПЦеИ∞жЬђеЬ∞зЪДGFSйЫЖзЊ§дЄ≠пЉМзДґеРОIndexз≥їзїЯе∞ЖдЉЪеѓєињЩдЄ™GFSйЫЖзЊ§дЄ≠е§ЪдЄ™жХ∞жНЃChunkињЫи°Меє≥и°МзЪДMapе§ДзРЖпЉМзФЯжИРе§ЪдЄ™KeyдЄЇURLпЉМvalueдЄЇhtmlй°µйЭҐзЪДйФЃеАЉеѓєпЉИKey-Value MapпЉЙпЉМжО•зЭАз≥їзїЯдЉЪеѓєињЩдЇЫеИЪзФЯжИРзЪДйФЃеАЉеѓєињЫи°МShuffleпЉИжЄЕзРЖпЉЙпЉМдєЛеРОз≥їзїЯдЉЪйАЪињЗReduceжУНдљЬжЭ•ж†єжНЃзЫЄеРМзЪДkeyеАЉпЉИдєЯе∞±жШѓURLпЉЙеРИеєґињЩдЇЫйФЃеАЉеѓєгАВ
жЬАеРОпЉМйАЪињЗMapReduceињЩдєИзЃАеНХзЪДзЉЦз®Лж®°еЮЛпЉМдЄНдїЕиГљзФ®дЇОе§ДзРЖе§ІиІДж®°жХ∞жНЃпЉМиАМдЄФиГље∞ЖеЊИе§ЪзєБзРРзЪДзїЖиКВйЪРиЧПиµЈжЭ•пЉМжѓФе¶ВиЗ™еК®еєґи°МеМЦпЉМиіЯиљљеЭЗи°°еТМжЬЇеЩ®еЃХжЬЇе§ДзРЖз≠ЙпЉМињЩж†Је∞ЖжЮБе§ІеЬ∞зЃАеМЦз®ЛеЇПеСШзЪДеЉАеПСеЈ•дљЬгАВMapReduceеПѓзФ®дЇОеМЕжЛђ"еИЖеЄГgrepпЉМеИЖеЄГжОТеЇПпЉМwebиЃњйЧЃжЧ•ењЧеИЖжЮРпЉМеПНеРС糥еЉХжЮДеїЇпЉМжЦЗж°£иБЪз±їпЉМжЬЇеЩ®е≠¶дє†пЉМеЯЇдЇОзїЯиЃ°зЪДжЬЇеЩ®зњїиѓСпЉМзФЯжИРGoogleзЪДжХідЄ™жРЬ糥зЪД糥еЉХ"з≠Йе§ІиІДж®°жХ∞жНЃе§ДзРЖеЈ•дљЬгАВYahooдєЯжО®еЗЇMapReduceзЪДеЉАжЇРзЙИжЬђHadoopпЉМиАМдЄФHadoopеЬ®дЄЪзХМдєЯеЈ≤зїП襀姲иІДж®°дљњзФ®гАВ
Sawzall
Sawzallеσ俕襀聧䪯жШѓжЮДеїЇеЬ®MapReduceдєЛдЄКзЪДйЗЗзФ®з±їдЉЉJavaиѓ≠ж≥ХзЪДDSLпЉИDomain-Specific LanguageпЉЙпЉМдєЯеПѓдї•иЃ§дЄЇеЃГжШѓеИЖеЄГеЉПзЪДAWKгАВеЃГдЄїи¶БзФ®дЇОеѓєе§ІиІДж®°еИЖеЄГеЉПжХ∞жНЃињЫи°Мз≠ЫйАЙеТМиБЪеРИз≠ЙйЂШзЇІжХ∞жНЃе§ДзРЖжУНдљЬпЉМеЬ®еЃЮзО∞жЦєйЭҐпЉМжШѓйАЪињЗиІ£йЗКеЩ®е∞ЖеЕґиљђеМЦдЄЇзЫЄеѓєеЇФзЪДMapReduceдїїеК°гАВйЩ§дЇЖGoogleзЪДSawzallдєЛе§ЦпЉМyahooжО®еЗЇдЇЖзЫЄдЉЉзЪДPigиѓ≠и®АпЉМдљЖеЕґиѓ≠ж≥Хз±їдЉЉдЇОSQLгАВ
еИЖеЄГеЉПжХ∞жНЃеЇУжКАжЬѓ
BigTable
зФ±дЇОеЬ®GoogleзЪДжХ∞жНЃдЄ≠ењГе≠ШеВ®PBзЇІдї•дЄКзЪДйЭЮеЕ≥з≥їеЮЛжХ∞жНЃжЧґеАЩпЉМжѓФе¶ВзљСй°µеТМеЬ∞зРЖжХ∞жНЃз≠ЙпЉМдЄЇдЇЖжЫіе•љеЬ∞е≠ШеВ®еТМеИ©зФ®ињЩдЇЫжХ∞жНЃпЉМGoogleеЉАеПСдЇЖдЄАе•ЧжХ∞жНЃеЇУз≥їзїЯпЉМеРНдЄЇ"BigTable"гАВBigTableдЄНжШѓдЄАдЄ™еЕ≥з≥їеЮЛзЪДжХ∞жНЃеЇУпЉМеЃГдєЯдЄНжФѓжМБеЕ≥иБФпЉИJoinпЉЙз≠ЙйЂШзЇІSQLжУНдљЬпЉМеПЦиАМдї£дєЛзЪДжШѓе§ЪзЇІжШ†е∞ДзЪДжХ∞жНЃзїУжЮДпЉМеєґжШѓдЄАзІНйЭҐеРСе§ІиІДж®°е§ДзРЖгАБеЃєйФЩжАІеЉЇзЪДиЗ™жИСзЃ°зРЖз≥їзїЯпЉМжЛ•жЬЙTBзЇІзЪДеЖЕе≠ШеТМPBзЇІзЪДе≠ШеВ®иГљеКЫпЉМдљњзФ®зїУжЮДеМЦзЪДжЦЗдїґжЭ•е≠ШеВ®жХ∞жНЃпЉМеєґжѓПзІТеПѓдї•е§ДзРЖжХ∞зЩЊдЄЗзЪДиѓїеЖЩжУНдљЬгАВ
дїАдєИжШѓе§ЪзЇІжШ†е∞ДзЪДжХ∞жНЃзїУжЮДеСҐпЉЯе∞±жШѓдЄАдЄ™з®АзЦПзЪДпЉМе§ЪзїізЪДпЉМжОТеЇПзЪДMapпЉМжѓПдЄ™CellзФ±и°МеЕ≥йФЃе≠ЧпЉМеИЧеЕ≥йФЃе≠ЧеТМжЧґйЧіжИ≥дЄЙзїіеЃЪдљНпЉОCellзЪДеЖЕеЃєжШѓдЄАдЄ™дЄНиІ£йЗКзЪДе≠Чзђ¶дЄ≤пЉМжѓФе¶ВдЄЛи°®е≠ШеВ®жѓПдЄ™зљСзЂЩзЪДеЖЕеЃєдЄО襀еЕґдїЦзљСзЂЩзЪДеПНеРСињЮжО•зЪДжЦЗжЬђгАВ еПНеРСзЪДURL com.cnn.wwwжШѓињЩи°МзЪДеЕ≥йФЃе≠ЧпЉЫcontentsеИЧе≠ШеВ®зљСй°µеЖЕеЃєпЉМжѓПдЄ™еЖЕеЃєжЬЙдЄАдЄ™жЧґйЧіжИ≥пЉМеЫ†дЄЇжЬЙдЄ§дЄ™еПНеРСињЮжО•пЉМжЙАдї•archorзЪДColumn FamilyжЬЙдЄ§еИЧпЉЪanchor: cnnsi.comеТМanchhor:my.look.caгАВColumn FamilyињЩдЄ™ж¶ВењµпЉМдљњеЊЧи°®еПѓдї•иљїжЭЊеЬ∞ж®™еРСжЙ©е±ХгАВдЄЛйЭҐжШѓеЃГеЕЈдљУзЪДжХ∞жНЃж®°еЮЛеЫЊпЉЪ
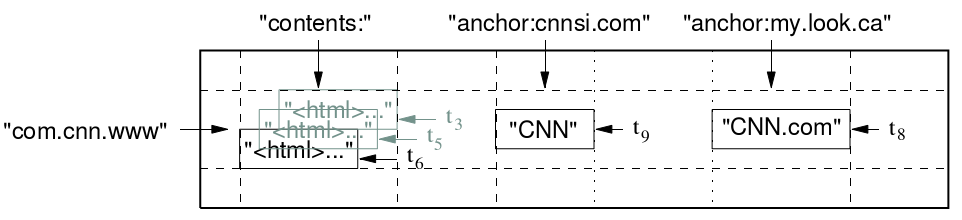
еЫЊ3. BigTableжХ∞жНЃж®°еЮЛеЫЊпЉИеПВ[4]пЉЙ
еЬ®зїУжЮДдЄКпЉМй¶ЦеЕИпЉМBigTableеЯЇдЇОGFSеИЖеЄГеЉПжЦЗдїґз≥їзїЯеТМChubbyеИЖеЄГеЉПйФБжЬНеК°гАВеЕґжђ°BigTableдєЯеИЖдЄЇдЄ§йГ®еИЖпЉЪеЕґдЄАжШѓMasterиКВзВєпЉМзФ®жЭ•е§ДзРЖеЕГжХ∞жНЃзЫЄеЕ≥зЪДжУНдљЬеєґжФѓжМБиіЯиљљеЭЗи°°гАВеЕґдЇМжШѓtabletиКВзВєпЉМдЄїи¶БзФ®дЇОе≠ШеВ®жХ∞жНЃеЇУзЪДеИЖзЙЗtabletпЉМеєґжПРдЊЫзЫЄеЇФзЪДжХ∞жНЃиЃњйЧЃпЉМеРМжЧґTabletжШѓеЯЇдЇОеРНдЄЇSSTableзЪДж†ЉеЉПпЉМеѓєеОЛзЉ©жЬЙеЊИе•љзЪДжФѓжМБгАВ
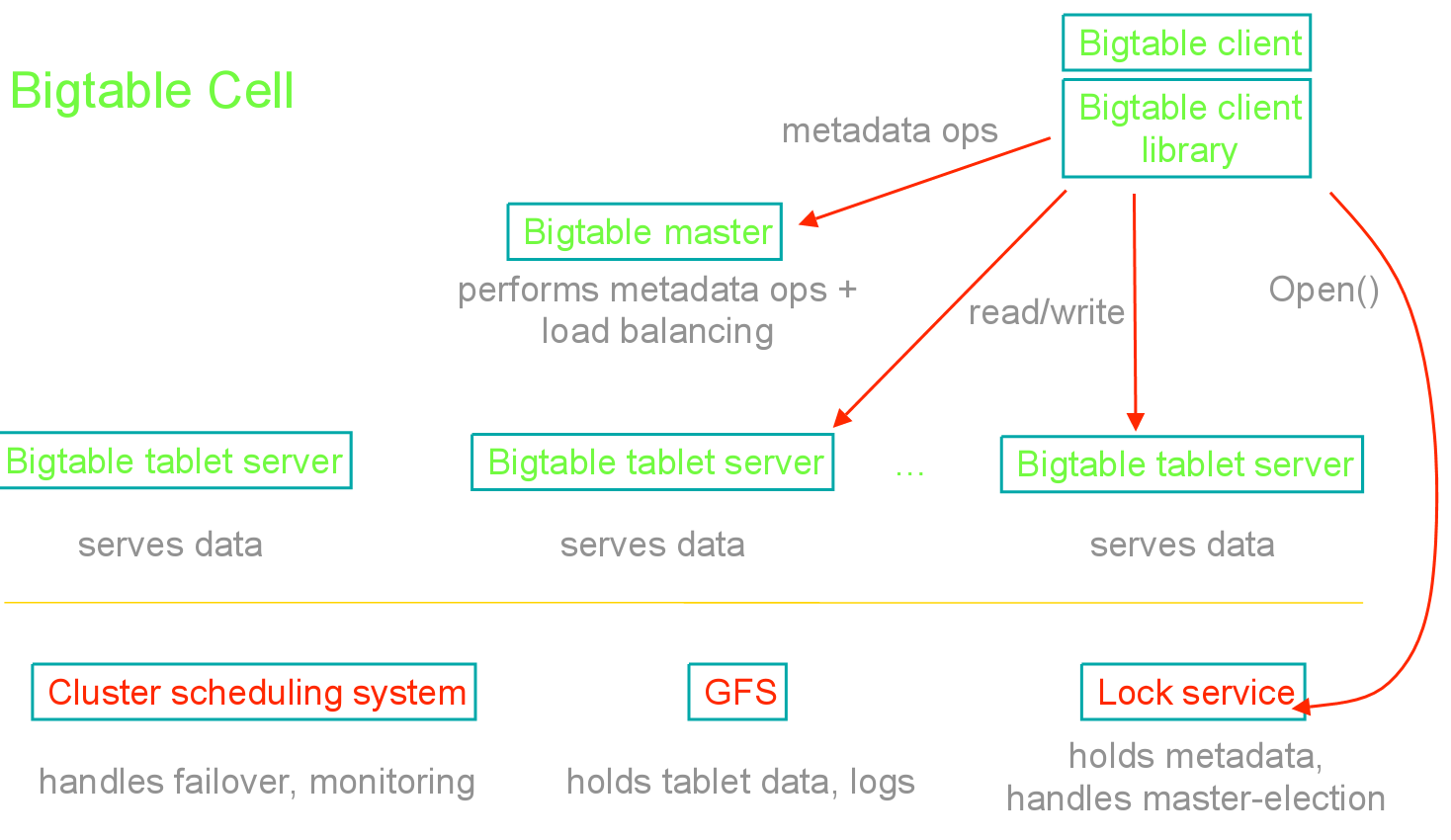
еЫЊ4. BigTableжЮґжЮДеЫЊпЉИеПВ[15]пЉЙ
BigTableж≠£еЬ®дЄЇGoogleеЕ≠еНБе§ЪзІНдЇІеУБеТМй°єзЫЃжПРдЊЫе≠ШеВ®еТМиОЈеПЦзїУжЮДеМЦжХ∞жНЃзЪДжФѓжТСеє≥еП∞пЉМеЕґдЄ≠еМЕжЛђжЬЙGoogle PrintгАБ OrkutгАБGoogle MapsгАБGoogle EarthеТМBloggerз≠ЙпЉМиАМдЄФGoogleиЗ≥е∞СињРи°МзЭА500дЄ™BigTableйЫЖзЊ§гАВ
йЪПзЭАGoogleеЖЕйГ®жЬНеК°еѓєйЬАж±ВзЪДдЄНжЦ≠жПРйЂШеТМжКАжЬѓзЪДдЄНжЦ≠еЬ∞еПСе±ХпЉМеѓЉиЗіеОЯеЕИзЪДBigTableеЈ≤зїПжЧ†ж≥Хжї°иґ≥зФ®жИЈзЪДйЬАж±ВпЉМиАМGoogleдєЯж≠£еЬ®еЉАеПСдЄЛдЄАдї£BigTableпЉМеРНдЄЇ"SpannerпЉИжЙ≥жЙЛпЉЙ"пЉМеЃГдЄїи¶БжЬЙдЄЛйЭҐињЩдЇЫBigTableжЙАжЧ†ж≥ХжФѓжМБзЪДзЙєжАІпЉЪ
- жФѓжМБе§ЪзІНжХ∞жНЃзїУжЮДпЉМжѓФе¶ВtableпЉМfamilieпЉМgroupеТМcoprocessorз≠ЙгАВ
- еЯЇдЇОеИЖе±ВзЫЃељХеТМи°МзЪДзїЖз≤ТеЇ¶зЪДе§НеИґеТМжЭГйЩРзЃ°зРЖгАВ
- жФѓжМБиЈ®жХ∞жНЃдЄ≠ењГзЪДеЉЇдЄАиЗіжАІеТМеЉ±дЄАиЗіжАІжОІеИґгАВ
- еЯЇдЇОPaxosзЃЧж≥ХзЪДеЉЇдЄАиЗіжАІеЙѓжЬђеРМж≠•пЉМеєґжФѓжМБеИЖеЄГеЉПдЇЛеК°гАВ
- жПРдЊЫиЃЄе§ЪиЗ™еК®еМЦжУНдљЬгАВ
- еЉЇе§ІзЪДжЙ©е±ХиГљеКЫпЉМиГљжФѓжМБзЩЊдЄЗеП∞жЬНеК°еЩ®зЇІеИЂзЪДйЫЖзЊ§гАВ
- зФ®жИЈеПѓдї•иЗ™еЃЪдєЙиѓЄе¶ВеїґињЯеТМе§НеИґжђ°жХ∞з≠ЙйЗНи¶БеПВжХ∞дї•йАВеЇФдЄНеРМзЪДйЬАж±ВгАВ
жХ∞жНЃеЇУSharding
Shardingе∞±жШѓеИЖзЙЗзЪДжДПжАЭпЉМиЩљзДґйЭЮеЕ≥з≥їеЮЛжХ∞жНЃеЇУжѓФе¶ВBigTableеЬ®GoogleзЪДдЄЦзХМдЄ≠еН†жЬЙйЭЮеЄЄйЗНи¶БзЪДеЬ∞дљНпЉМдљЖжШѓйЭҐеѓєдЉ†зїЯOLTPеЇФзФ®пЉМжѓФе¶ВеєњеСКз≥їзїЯпЉМGoogleињШжШѓйЗЗзФ®дЉ†зїЯзЪДеЕ≥з≥їеЮЛжХ∞жНЃеЇУжКАжЬѓпЉМдєЯе∞±жШѓMySQLпЉМеРМжЧґзФ±дЇОGoogleжЙАйЬАи¶БйЭҐеѓєжµБйЗПйЭЮеЄЄеЈ®е§ІпЉМжЙАдї•GoogleеЬ®жХ∞жНЃеЇУе±ВйЗЗзФ®дЇЖеИЖзЙЗпЉИShardingпЉЙзЪДж∞іеє≥жЙ©е±ХпЉИScale OutпЉЙиІ£еЖ≥жЦєж°ИпЉМеИЖзЙЗжШѓеЬ®дЉ†зїЯеЮВзЫіжЙ©е±ХпЉИScale UpпЉЙзЪДеИЖеМЇж®°еЉПдЄКзЪДдЄАзІНжПРеНЗпЉМдЄїи¶БйАЪињЗжЧґйЧіпЉМиМГеЫіеТМйЭҐеРСжЬНеК°з≠ЙжЦєеЉПжЭ•е∞ЖдЄАдЄ™е§ІеЮЛзЪДжХ∞жНЃеЇУеИЖжИРе§ЪзЙЗпЉМеєґдЄФињЩдЇЫжХ∞жНЃзЙЗеПѓдї•иЈ®иґКе§ЪдЄ™жХ∞жНЃеЇУеТМжЬНеК°еЩ®жЭ•еЃЮзО∞ж∞іеє≥жЙ©е±ХгАВ
GoogleжХіе•ЧжХ∞жНЃеЇУеИЖзЙЗжКАжЬѓдЄїи¶БжЬЙдЄЛйЭҐињЩдЇЫдЉШзВєпЉЪ
- жЙ©е±ХжАІеЉЇпЉЪеЬ®GoogleзФЯдЇІзОѓеҐГдЄ≠пЉМеЈ≤зїПжЬЙжФѓжМБдЄКеНГеП∞жЬНеК°еЩ®зЪДMySQLеИЖзЙЗйЫЖзЊ§гАВ
- еРЮеРРйЗПжГКдЇЇпЉЪйАЪињЗеЈ®е§ІзЪДMySQLеИЖзЙЗйЫЖзЊ§иГљжї°иґ≥еЈ®йЗПзЪДжߕ胥胣ж±ВгАВ
- еЕ®зРГе§ЗдїљпЉЪдЄНдїЕеЬ®дЄАдЄ™жХ∞жНЃдЄ≠ењГињШжШѓеЬ®еЕ®зРГзЪДиМГеЫіпЉМGoogleйГљдЉЪеѓєMySQLзЪДеИЖзЙЗжХ∞жНЃињЫи°Ме§ЗдїљпЉМињЩж†ЈдЄНдїЕиГљдњЭжК§жХ∞жНЃпЉМиАМдЄФжЦєдЊњжЙ©е±ХгАВ
еЬ®еЃЮзО∞жЦєйЭҐпЉМдЄїи¶БеПѓеИЖдЄЇдЄ§еЭЧпЉЪеЕґдЄАжШѓеЬ®MySQL InnoDBеЯЇз°АдЄКжЈїеК†дЇЖжХ∞жНЃеЇУеИЖзЙЗзЪДжКАжЬѓгАВеЕґдЇМжШѓеЬ®ORMе±ВзЪДHibernateзЪДеЯЇз°АдЄКдєЯжЈїеК†дЇЖзЫЄеЕ≥зЪДеИЖзЙЗжКАжЬѓпЉМеєґжФѓжМБиЩЪжЛЯеИЖзЙЗпЉИVirtual ShardпЉЙжЭ•дЊњдЇОеЉАеПСеТМзЃ°зРЖгАВеРМжЧґGoogleдєЯеЈ≤зїПе∞ЖињЩдЄ§жЦєйЭҐзЪДдї£з†БжПРдЇ§зїЩзЫЄеЕ≥зїДзїЗгАВ
жХ∞жНЃдЄ≠ењГдЉШеМЦжКАжЬѓ
жХ∞жНЃдЄ≠ењГйЂШжЄ©еМЦ
е§ІдЄ≠еЮЛжХ∞жНЃдЄ≠ењГзЪДPUEпЉИPower Usage EffectivenessпЉЙжЩЃйБНеЬ®2еЈ¶еП≥пЉМдєЯе∞±жШѓеЬ®жЬНеК°еЩ®з≠ЙиЃ°зЃЧиЃЊе§ЗдЄКиАЧ1еЇ¶зФµпЉМеЬ®з©Їи∞Гз≠ЙиЊЕеК©иЃЊе§ЗдЄКдєЯи¶БжґИиАЧдЄАеЇ¶зФµгАВеѓєдЄАдЇЫйЭЮеЄЄеЗЇиЙ≤зЪДжХ∞жНЃдЄ≠ењГпЉМжЬАе§ЪдєЯе∞±иГљиЊЊеИ∞1.7пЉМдљЖжШѓGoogleйАЪињЗдЄАдЇЫжЬЙжХИзЪДиЃЊиЃ°дљњйГ®еИЖжХ∞жНЃдЄ≠ењГеИ∞иЊЊдЇЖдЄЪзХМйҐЖеЕИзЪД1.2пЉМеЬ®ињЩдЇЫиЃЊиЃ°ељУдЄ≠пЉМеЕґдЄ≠жЬАжЬЙзЙєиЙ≤зЪДиОЂињЗдЇОжХ∞жНЃдЄ≠ењГйЂШжЄ©еМЦпЉМдєЯе∞±жШѓиЃ©жХ∞жНЃдЄ≠ењГеЖЕзЪДиЃ°зЃЧиЃЊе§ЗињРи°МеЬ®еБПйЂШзЪДжЄ©еЇ¶дЄЛпЉМGoogleзЪДиГљжЇРжЦєйЭҐзЪДжАїзЫСErik TeetzelеЬ®и∞ИеИ∞ињЩзВєзЪДжЧґеАЩиѓіпЉЪ"жЩЃйАЪзЪДжХ∞жНЃдЄ≠ењГеЬ®70еНОж∞ПеЇ¶пЉИ21жСДж∞ПеЇ¶пЉЙдЄЛйЭҐеЈ•дљЬпЉМиАМжИСдїђеИЩжО®иНР80еНОж∞ПеЇ¶пЉИ27жСДж∞ПеЇ¶пЉЙ"гАВдљЖжШѓеЬ®жПРйЂШжХ∞жНЃдЄ≠ењГзЪДжЄ©еЇ¶жЦєйЭҐдЉЪжЬЙдЄ§дЄ™еЄЄиІБзЪДйЩРеИґжЭ°дїґпЉЪеЕґдЄАжШѓжЬНеК°еЩ®иЃЊе§ЗзЪДеі©жЇГзВєпЉМеЕґдЇМжШѓз≤Њз°ЃзЪДжЄ©еЇ¶жОІеИґгАВе¶ВжЮЬеБЪе•љињЩдЄ§зВєпЉМжХ∞жНЃдЄ≠ењГе∞±иГље§ЯеЬ®йЂШжЄ©дЄЛеЈ•дљЬпЉМеЫ†дЄЇеБЗиЃЊжХ∞жНЃдЄ≠ењГзЪДзЃ°зРЖеСШиГљеѓєжХ∞жНЃдЄ≠ењГзЪДжЄ©еЇ¶ињЫи°Мж≠£иіЯ1/2еЇ¶зЪДи∞ГиКВпЉМињЩе∞ЖдљњжЬНеК°еЩ®иЃЊе§ЗиГљеЬ®еі©жЇГзВє5еЇ¶дєЛеЖЕеЈ•дљЬпЉМиАМдЄНжШѓеЄЄиІБзЪД20еЇ¶дєЛеЖЕпЉМињЩж†ЈжЧҐзїПжµОпЉМеПИеЃЙеЕ®гАВињШжЬЙпЉМдЄЪзХМдЉ†и®АIntelдЄЇGoogleжПРдЊЫжКЧйЂШжЄ©иЃЊиЃ°зЪДеЃЪеИґиКѓзЙЗпЉМдљЖдЇСиЃ°зЃЧзХМзЪДй°ґзЇІдЄУеЃґJames HamiltonиЃ§дЄЇдЄН姙еПѓиГљпЉМеЫ†дЄЇиЩљзДґе§ДзРЖеЩ®дєЯйЭЮеЄЄжГІжАХзГ≠йЗПпЉМдљЖжШѓдЄОеЖЕе≠ШеТМз°ђзЫШзЫЄжѓФињШжШѓеЉЇеЊИе§ЪпЉМжЙАдї•е§ДзРЖеЩ®еЬ®жКЧйЂШжЄ©иЃЊиЃ°дЄ≠еєґдЄНжШѓдЄАдЄ™ж†ЄењГеЫ†зі†гАВеРМжЧґдїЦдєЯйЭЮеЄЄжФѓжМБдљњжХ∞жНЃдЄ≠ењГйЂШжЄ©еМЦињЩдЄ™жГ≥ж≥ХпЉМиАМдЄФжЬЯжЬЫе∞ЖжЭ•жХ∞жНЃдЄ≠ењГзФЪиЗ≥иГљињРи°МеЬ®40жСДж∞ПеЇ¶дЄЛпЉМињЩж†ЈдЄНдїЕиГљиКВзЬБз©Їи∞ГжЦєйЭҐзЪДжИРжЬђпЉМиАМдЄФеѓєзОѓеҐГдєЯеЊИжЬЙеИ©гАВ
12VзԵ汆
зФ±дЇОдЉ†зїЯзЪДUPSеЬ®иµДжЇРжЦєйЭҐжѓФиЊГжµ™иієпЉМжЙАдї•GoogleеЬ®ињЩжЦєйЭҐеП¶иЊЯиєКеЊДпЉМйЗЗзФ®дЇЖзїЩжѓПеП∞жЬНеК°еЩ®йЕНдЄАдЄ™дЄУзФ®зЪД12VзԵ汆зЪДеБЪж≥ХжЭ•жЫњжНҐдЇЖеЄЄзФ®зЪДUPSпЉМе¶ВжЮЬдЄїзФµжЇРз≥їзїЯеЗЇзО∞жХЕйЪЬпЉМе∞ЖзФ±иѓ•зԵ汆иіЯиі£еѓєжЬНеК°еЩ®дЊЫзФµгАВиЩљзДґе§ІеЮЛUPSеПѓдї•иЊЊеИ∞92%еИ∞95%зЪДжХИзОЗпЉМдљЖжШѓжѓФиµЈеЖЕзљЃзԵ汆зЪД99.99%иАМи®АжШѓйЭЮеЄЄжНЙи•ЯиІБиВШзЪДпЉМиАМдЄФзФ±дЇОиГљйЗПеЃИжБТзЪДеОЯеЫ†пЉМеѓЉиЗійВ£дєИжܙ襀UPSеЕЕеИЖеИ©зФ®зЪДзФµеКЫдЉЪ襀蚐еМЦжИРзГ≠иГљпЉМињЩе∞ЖеѓЉиЗізФ®дЇОз©Їи∞ГзЪДиГљиАЧзЫЄеЇФеЬ∞жФАеНЗпЉМдїОиАМиµ∞еЕ•дЄАдЄ™жБґжАІеЊ™зОѓгАВеРМжЧґеЬ®зФµжЇРжЦєйЭҐдєЯжЬЙз±їдЉЉзЪД"з•ЮжЭ•дєЛзђФ"пЉМжЩЃйАЪзЪДжЬНеК°еЩ®зФµжЇРдЉЪеРМжЧґжПРдЊЫ5VеТМ12VзЪДзЫіжµБзФµгАВдљЖжШѓGoogleиЃЊиЃ°зЪДжЬНеК°еЩ®зФµжЇРеП™иЊУеЗЇ12VзЫіжµБзФµпЉМењЕи¶БзЪДиљђжНҐеЬ®дЄїжЭњдЄКињЫи°МпЉМиЩљзДґињЩзІНиЃЊиЃ°дЉЪдљњдЄїжЭњзЪДжИРжЬђеҐЮеК†1зЊОеЕГеИ∞2зЊОеЕГпЉМдљЖжШѓеЃГдЄНдїЕиГљдљњзФµжЇРиГљеЬ®жО•ињСеЕґе≥∞еАЉеЃєйЗПзЪДжГЕеЖµдЄЛињРи°МпЉМиАМдЄФеЬ®йУЬзЇњдЄКдЉ†иЊУзФµжµБжЧґжХИзОЗжЫійЂШгАВ
жЬНеК°еЩ®жХіеРИ
и∞ИеИ∞иЩЪжЛЯеМЦзЪДжЭАжЙЛйФПжЧґпЉМзђђдЄАдЄ™иЃ©дЇЇжГ≥еИ∞иВѓеЃЪжШѓжЬНеК°еЩ®жХіеРИпЉМиАМдЄФжЩЃйБНиГљеЃЮзО∞1:8зЪДжХіеРИзОЗжЭ•йЩНдљОеРДжЦєйЭҐзЪДжИРжЬђгАВжЬЙиґ£зЪДжШѓпЉМGoogleеЬ®з°ђдїґжЦєйЭҐдєЯеЉХеЕ•з±їдЉЉжЬНеК°еЩ®жХіеРИзЪДжГ≥ж≥ХпЉМеЃГзЪДеБЪж≥ХжШѓеЬ®дЄАдЄ™жЬЇзЃ±е§Іе∞ПзЪДз©ЇйЧіеЖЕжФЊзљЃдЄ§еП∞жЬНеК°еЩ®пЉМињЩдЇЫеБЪзЪДе•ље§ДжЬЙеЊИе§ЪпЉМй¶ЦеЕИпЉМеЗПе∞ПдЇЖеН†еЬ∞йЭҐзІѓгАВеЕґжђ°пЉМйАЪињЗиЃ©дЄ§еП∞жЬНеК°еЩ®еЕ±дЇЂиѓЄе¶ВзФµжЇРз≠ЙиЃЊе§ЗпЉМжЭ•йЩНдљОиЃЊе§ЗеТМиГљжЇРз≠ЙжЦєйЭҐзЪДжКХеЕ•гАВ
жЬђзѓЗзїУжЭЯпЉМдЄЛзѓЗе∞ЖзМЬжГ≥дЄАдЄЛGoogleжХідљУжЮґжЮДгАВ
--EOF--



зЫЄеЕ≥жО®иНР
appengine-java-sdk-1.3.1 GoogleAppеЉАеПСзЪДSDKпЉИJavaзЙИпЉЙ
и∞Јж≠МappengineдЊЭиµЦеЇУпЉМGWTзЉЦиѓСйЬАи¶БеЉХеЕ•ж≠§еЇУпЉМжЦєдЊње•љзФ®пЉБ
1гАБзФ®winrarжЙЊеЉАeclipse\plugins\com.google.appengine.eclipse.sdkbundle_1.2.0.v200904062254\appengine-java-sdk-1.2.0\lib\appengine-tools-api.jarгАВ зФ®дљ†дЄЛиљљзЪДеМЕдЄ≠Application.classжЫњжНҐom.google.appengine....
Programming-Google-App-Engine-with-Python-Build-and-Run-Scalable-Python-Apps-on-Google-s-Infrastructure.pdf
google-appengine-java-sdk-1.9.3 еЫЇеЃЮеОЛзЉ©, еЄ¶жБҐе§НиЃ∞ељХ жАїеЕ±дЄЙдЄ™еИЖеНЈ, ж≠§дЄЇ, part1
google-appengine-java-sdk-1.9.3 еЫЇеЃЮеОЛзЉ©, еЄ¶жБҐе§НиЃ∞ељХ жАїеЕ±дЄЙдЄ™еИЖеНЈ, ж≠§дЄЇpart3
Google appengine docsжЦЗж°£пЉМ2010-12-02жЫіжЦ∞зљСй°µзЙИzip
appengine for java sdk,йЬАи¶Бjdk1.7жИЦjdk1.8пЉМjavac compiler иЃЊзљЃдЄЇjdk1.7пЉМдЄАеЕ±еМЕеРЂ3дЄ™йГ®еИЖгАВ
This practical guide shows intermediate and advanced web and mobile app developers how to build highly scalable Java applications in the cloud with Google App Engine. The flagship of Google's Cloud ...
JavaзЙИжЬђзЪДappengine пЉМжПРдЊЫдЄЛиљљгАВдЇ≤жµЛеПѓзФ®дЇОapp inventorињРи°МжЧґжЬНеК°еЩ®зЪДжР≠еїЇпЉМдєЯеПѓзФ®дЇОеЕґеЃГиљѓдїґзЪДеЉАеПС
google-app-engine-ranklist-ndb google-app-engine-ranklist-ndbжШѓжЭ•иЗ™зЪДеИЖжФѓй°єзЫЃ еѓєеОЯеІЛдї£з†БињЫи°МдЇЖдї•дЄЛжЫіжФє дљњзФ®ndbдї£жЫњеОЯеІЛжХ∞жНЃе≠ШеВ® еЄ¶жЬЙжТ≠жФЊеЩ®еРНзІ∞зЪДget_scoreеЗљжХ∞ еЯЇжЬђжµЛиѓХдї£з†Б иѓ•й°єзЫЃеМЕжЛђеОЯеІЛе≠ШеВ®еЇУдЄ≠зЪДз§ЇдЊЛ...
иµДжЇРеИЖз±їпЉЪPythonеЇУ жЙАе±Юиѓ≠и®АпЉЪPython иµДжЇРеЕ®еРНпЉЪrod.recipe.appengine-1.0.0b1-py2.5.egg иµДжЇРжЭ•жЇРпЉЪеЃШжЦє еЃЙи£ЕжЦєж≥ХпЉЪhttps://lanzao.blog.csdn.net/article/details/101784059
еЬ®жР≠еїЇWebRTC(AppRTC)жЧґпЉМжИСдїђдЉЪйБЗеИ∞йЬАи¶БйГ®зљ≤Google App EngineзЪДйЪЊйҐШпЉМеєґдЄФжЬАињСеҐЩзЪДеОЙеЃ≥пЉМжЙАдї•жИСзЙєеЬ∞жККжИСзПНиЧПзЪДGoogle App Engine жЬАжЦ∞зЙИ(2020-7-5)еИЖдЇЂеЗЇжЭ•пЉМеЄМжЬЫеПѓдї•жЦєдЊњжГ≥жР≠еїЇWebRTC(AppRTC)зЪДеРМе≠¶дїђ
Google App Engine is a web application hosting service. By вАЬweb application,вАЭ we mean an application or service accessed over the Web, usually with a web browser: storefronts with shopping carts, ...
clock.rar ињЩжШѓжИСдїК姩еБЪзЪДдЄАдЄ™еЯЇдЇОgoogle app engineеЖЩзЪДдЄАдЄ™еЬ®иѓ•еє≥еП∞дЄКеЉАеПСappзЪДз§ЇдЊЛпЉМйАЪињЗиѓ•з§ЇдЊЛзЪДе≠¶дє†пЉМжИСдїђеПѓдї•еЊИењЂдЄКжЙЛе≠¶дЉЪжАОж†ЈеЬ®GAEдЄКеЉАеПСе±ЮдЇОдљ†зЪДеЇФзФ®з®ЛеЇПдЇЖпЉМеЄМжЬЫеѓєе§ІеЃґжЬЙзФ®пЉБ
part2 http://download.csdn.net/detail/u011029071/5987179 part3 http://download.csdn.net/detail/u011029071/5986923 еЃЙи£ЕжЦєж≥Хhttp://blog.csdn.net/u011029071/article/details/10143841
appengine-maven-plugin жФѓжМБApp EngineеЉАеПСдЇЇеСШзЪДMavenжПТдїґгАВ еЬ®жИСдїђзЪДеЃШжЦєгАКдљњзФ®Apache MavenгАЛжЦЗж°£зЂЩзВєдЄКеПѓдї•жЙЊеИ∞йТИеѓєзФ®жИЈзЪДжЫіеЕ®йЭҐзЪДжЦЗж°£гАВ Apache MavenжШѓдЄАдЄ™иљѓдїґй°єзЫЃзЃ°зРЖеТМзРЖиІ£еЈ•еЕЈгАВ еЃГиГље§ЯжЮДеїЇжИШдЇЙжЦЗдїґдї•...
A good book to learn Google App Engine.
Google App Engine Documentation